
Platform
Use Cases
ACCOUNT SECURITY
Account TakeoverMulti-AccountingAccount SharingIDENTITY & FRAUD
Synthetic IdentitiesIncentive AbuseTransaction FraudPricing
Docs
February 5, 2019
Each correct answer from a visitor that adds more confidence to our estimation of the right answer is compensated at a rate determined by a real-time bidding system for each type of simple task offered by the service.
Approximate formula:
Final Reward = “Useful” Answers[1] * Reward per Task * Fill Rate
[1] Correct answers from humans who correctly answered most questions they received.
hCaptcha creates a brand new revenue stream for websites by rewarding them when their users solve a hCaptcha. Each hCaptcha is a simple task that provides human labor for companies building machine learning datasets.
Operating the hCaptcha service poses an interesting mathematical challenge.
Our systems must combine multiple answers to the same set of questions from different people with a small percentage of known answers (“ground truth”) in order to determine the “likely right answer” with high accuracy.

Looks like a midi to me. Most people agreed.
Consider this scenario:
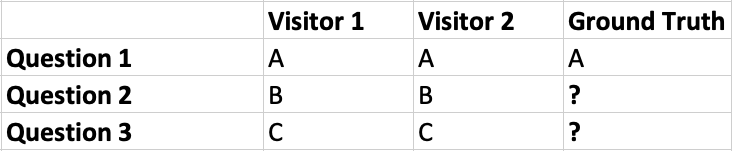
Visitor 1 answers all questions identically to Visitor 2, and both answer question 1 in the same way as the ground truth data. We now start to build our confidence in several properties of both the visitors and the questions with unknown answers:
Our job is to compute the “likely right answer” for each question that customers ask, using the fewest number of repetitions per question to reach confidence in that answer.
Our goal is to be able to use answers from visitors who are less than 100% accurate, increasing system efficiency. This increases our work capacity, and thus the rewards we can give to each website for the same amount of traffic.
Microwork platforms generally offer the ability to set requirements for a specific minimum worker accuracy rate and prior work quantity. This is done in order to limit the workers completing a task to those likely to be correct.
A survey of these sites shows that many jobs accept only answers from workers with at least 95% accuracy and 50-100 previous tasks completed.
hCaptcha does not have this luxury. We must ask questions of bots, malicious humans, and most importantly of users for whom we have no prior history.
We need to be as accurate as possible in our judgment to keep out bots, and as efficient as possible in the number of times we ask a question to maximize site earnings and system throughput.
We also need to prevent automated attacks and collusions from fooling our systems into accepting the wrong answer just because multiple people say it is true.
Doing this without a large number of prior answers from the same visitor is also tricky. In fact, we may only get 3 or 9 answers from a particular visitor.

Did you realize this one screen is asking nine separate questions?
This is a difficult task in applied probability theory, but we have made substantial progress.
Our confidence models are already quite good, and are continuously refined as more data comes in.
This lets us assign value to answers from users who are not 100% correct, or 95% correct. Even users who are only 90% or a little less correct are still helpful within our models.
And we can do it with just a few answers from them! Much more efficient than requiring 95% accuracy across 50–100 answers.
This is important because we care about visitor privacy.
We are selling work rather than ads, so we have no need to eternally identify and track visitors across sites, devices, browsers, and so on in order to share that information with advertisers who need user demographics.
A visitor from Indonesia is just as valuable as a visitor from Germany so long as they can answer a simple question with the same accuracy.
Our models can also detect bad behavior with very little historical data. We thus prefer to retain the minimum amount of information about visitors necessary for the system to function while giving them a good experience, i.e. not re-asking too often once we think they’re probably non-malicious humans.
Keeping Out Bad Actors
Despite the constraints above, what we don’t want to do is compensate bad actors or people trying to game the system.
Consider the following:

Both visitors in Scenario 1 should receive a reward: their answers added confidence to the results when we ran the final computations.
If a visitor is only 50% correct as in Scenario 2, they’re not providing any increased confidence (i.e. value) at all: their answers are no better than random chance.
Giving them a reward would reduce the total pool available for good actors, so our metric for rewards is “Useful Human Answers”; answers determined to be from bots are not rewarded. Answers from malicious or inept humans are also not valuable to the system, and are equally valued at zero.
Finally, we have to consider a unique property of the hCaptcha system: our users depend on it to keep out malicious actors!
We cannot turn it off when we run out of compensated tasks, or when a site sends a large volume of bad traffic to us.
Similarly, we need to use some of the work flowing through to ensure accuracy and calibrate our systems: if we never asked questions to which we already know the answer we would be unable to achieve the same confidence. This means that each quarter we adjust the rewards for that period based on the percentage of tasks filled by paying customers vs. system calibration.
Ad networks use the term “fill rate” to refer to the percentage of available ad slots filled by paying customers. In our case this refers to the percentage of available “work slots” used for rewarded work.
With the increasing popularity of machine learning, we have seen many publishers show interest in applying their rewards directly to annotation services. We plan to make this easier over the coming months.
For publishers who wish to simply redeem their rewards for USD, we operate on a quarterly basis. This timeline is driven by underlying rhythms of the business. Because we work with large enterprise customers the payment cycles are rarely short. Aligning payouts with accounts receivable reduces business risk and makes our operating model safe and sustainable, which ultimately benefits everyone.
At the moment requested work exceeds supply, so we have a 100% fill rate aside from system calibration tasks. Temporary imbalances in supply and demand are a common occurrence in two-sided marketplaces, so we expect that in the future this could go down: most ad networks promise a fill rate of 25–50%, for example.
However, as our models improve each site’s earnings potential goes up: this is because getting more confidence out of each visitor and each answer effectively increases the available work slots for a given site.
We are also introducing new job types on a regular cadence to meet customer demand, and working steadily to make our products more useful and timely for the customer, which should also increase publisher revenues.
Finally, we’d like to thank you for supporting us on this journey.
We are working hard to create a new revenue stream that does not require selling your visitors’ identity as the product. Making this service work for both users and customers is an exciting but challenging mission, and your patience and encouragement go a long way.
Your comments, questions, and suggestions are also welcome: email us any time at support@hcaptcha.com.
— Eli, Alex, and the entire hCaptcha team















